DARTS+:DARTS 搜索为何需要早停?
提示您,本文原题为 -- DARTS+:DARTS 搜索为何需要早停?
机器之心专栏
作者:Weiran Huang
本文是一篇介绍 DART+ 的专栏文章 , 作者们提出一种可微分的神经网络架构搜索算法 DARTS+ , 将早停机制(early stopping)引入到原始的 DARTS[1] 算法中 , 不仅减小了 DARTS 搜索的时间 , 而且极大地提升了 DARTS 的性能 。 相关论文《DARTS+: Improved Differentiable Architecture Search with Early Stopping》已经公开(相关代码稍后也会开源) 。
论文地址:https://www.weiranhuang.com/publications/DARTS+.pdf
DARTS+ 在原始 DARTS 算法基础上只需简单地加入一条早停机制 , 就可以在 CIFAR10、CIFAR100 和 ImageNet 上取得 2.32%、14.87% 和 23.7% 的错误率 , 超越一系列现有的 DARTS 改进算法 , 包括 SNAS[2]、P-DARTS[3]、XNAS[4]、PC-DARTS[5] 等 。
在模型大小相当的情况下 , DARTS+ 可以达到与谷歌提出的 EfficientNet[6] 相同的性能 , 但是搜索时间却远远小于 EfficientNet , 再叠加上一些常用的 tricks , 在 ImageNet 上可以达到 22.5% 的错误率!早停机制的引入 , 让原本在搜索时间上具有显著优势的基于「可微分」的架构搜索方法 , 在性能上也开始超越基于「强化学习」或「演化算法」的架构搜索方法 , 极大地增加了「可微分架构搜索」的研究价值和应用范围 。
简介
神经网络架构搜索(Neural Architecture Search , NAS)在自动机器学习(AutoML)中扮演着重要的角色 , 近来获得越来越多的关注 。 用 NAS 搜索得到的神经网络架构已经在多种任务上超越了专家手工设计的网络架构 , 包括物体分类、物体检测、推荐系统等 。
神经网络架构搜索的常见做法是首先设计一个架构搜索空间 , 然后用某种搜索策略 , 从中找出一个最优的网络架构 。 早期的方案是基于强化学习(RL)或者演化算法(Evolutionary Algorithm)来搜索一个有效的网络架构 , 但是会耗费大量的计算资源(上千个 GPU days) , 不经济也不环保 。 后来 , 一些 One-Shot 的方案相继被提出 , 其中最具代表性的是 DARTS[1] 算法(Differentiable Architecture Search , 可微分的神经网络架构搜索) 。 它把搜索空间从离散的放松到连续的 , 从而能够用梯度下降来同时搜索架构和学习权重 。 具体来说 , DARTS 使用了如下的两层优化(Bi-Level Optimization)来搜索:
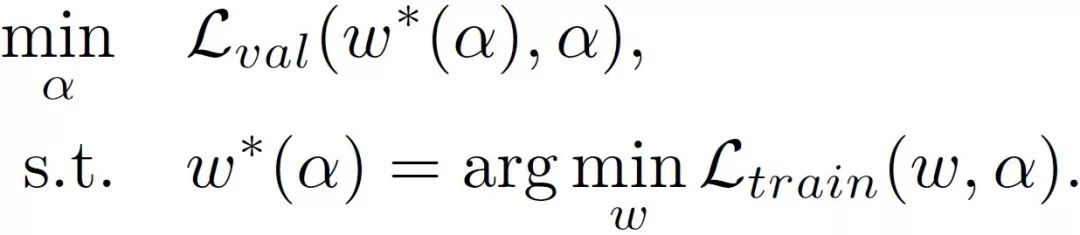
DARTS+:DARTS 搜索为何需要早停?// //
Bi-Level Optimization in DARTS
其中 , alpha 是架构的参数 , w 是 alpha 对应的模型权重 。 前者利用 validation data 来进行更新 , 后者利用 training data 来进行更新 。 具体细节可以参看 DARTS 的原文 。 DARTS 成功把搜索时间从上千个 GPU days 减少到了几个 GPU days 。
DARTS 算法的问题
DARTS 算法有一个严重的问题 , 就是当搜索轮数过大时 , 搜索出的架构中会包含很多的 skip-connect , 从而性能会变得很差 。 我们把这个现象叫做 Collapse of DARTS 。
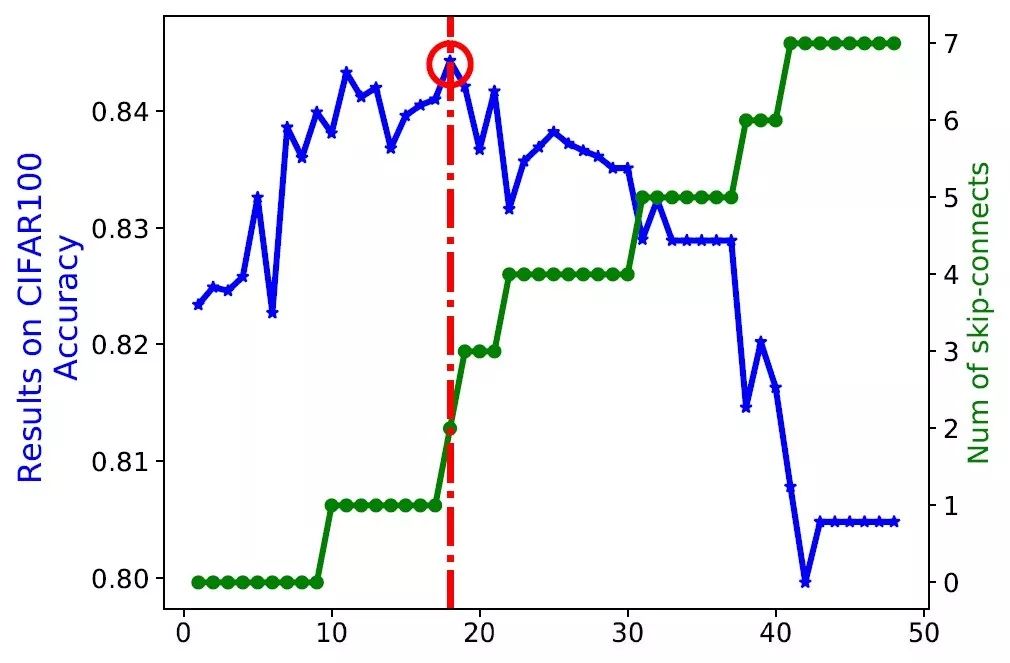
举个例子 , 让我们来考虑在 CIFAR100 上用 DARTS 做搜索 。 从下图可以看出 , 当 search epoch(横轴)比较大的时候 , skip-connect 的 alpha 值(绿线)将变得很大 。

DARTS+:DARTS 搜索为何需要早停?// //
Alpha Values in The Shallowest Edge
因此 , 在 DARTS 最后选出的网络架构中 , skip-connect 的数量也会随着 search epoch 变大而越来越多 , 如下图中的绿线所示 。
DARTS+:DARTS 搜索为何需要早停?// //
在一个节点数固定的 cell 中 , skip-connect 的数量越多 , 会导致网络变得越浅 。 相比于深度网络 , 浅度网络可学习的参数更少 , 具有的表达能力更弱 。 因此 , 在 DARTS 搜出的网络架构中 , skip-connect 的数量太多会导致性能急剧变差 。 例如 , 在上图中 , 当 skip-connect 的数量超过 2 个的时候 , 网络的性能(蓝线)开始降低 。 下图直观展示了随着 search epoch 变大 , 网络结构由深变浅的过程 。
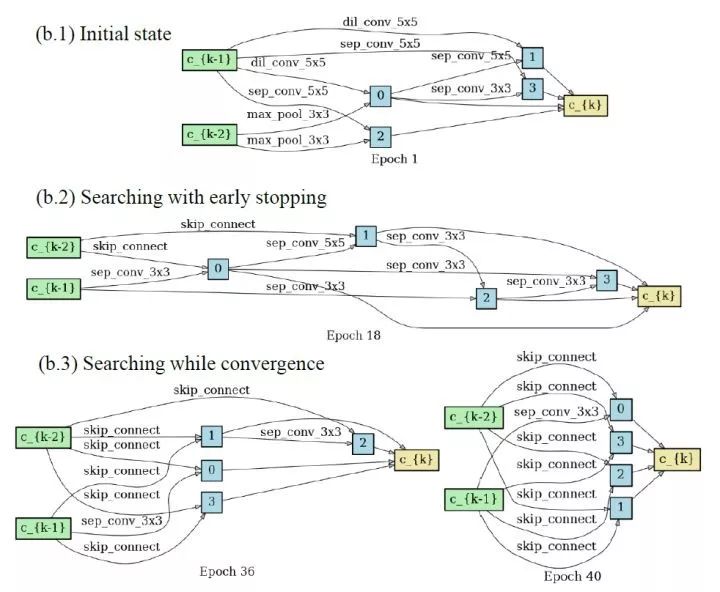
DARTS+:DARTS 搜索为何需要早停?// //
不同 search epoch 的情形下 , 在 CIFAR100 上用 DARTS 挑选出的网络结构图
DARTS 发生 Collapse 背后的原因是在两层优化中 , alpha 和 w 的更新过程存在先合作(cooperation)后竞争(competition)的问题 。 粗略来说 , 在刚开始更新的时候 , alpha 和 w 是一起被优化 , 从而 alpha 和 w 都是越变越好 。 渐渐地 , 两者开始变成竞争关系 , 由于 w 在竞争中比 alpha 更有优势(比如 , w 的参数量大于 alpha 的参数量 , One-Shot 模型在大多数 alpha 下都能收敛 , 等等) , alpha 开始被抑制 , 因此网络架构出现了先变好后变差的结果 , 也就是上上图中蓝线的情况 。
具体来说 , 在搜索过程的初始阶段 , One-Shot 模型欠拟合到数据集 , 因此在搜索过程刚开始的时候 , alpha 和 w(也就是 One-Shot 模型的参数)都会朝着变好的方向更新 , 这就是合作的阶段 。 由于整个 One-Shot 模型中 , 前面的 cell 比后面的 cell 能接触到更干净的数据 , 如果我们允许不同的 cell 可以拥有不同的网络结构(打破 DARTS 中 cell 共享网络结构的设定) , 那么前面的 cell 会比后面的 cell 更快地学到特征 。
一旦前面的 cell 已经学到了不错的特征表达 , 而后面的 cell 学到的特征表达相对较差 , 那么后面的 cell 接下来会倾向于选择 skip-connect , 来把前面 cell 已经学好的特征表达直接传递到后面 。 下图是打破 DARTS 中 cell 共享网络结构的设定下 , 搜出来的网络结构图:可以看到 , 前面的 cell 大部分都是卷积算子 , 而靠后的 cell 大部分都是 skip-connect 。
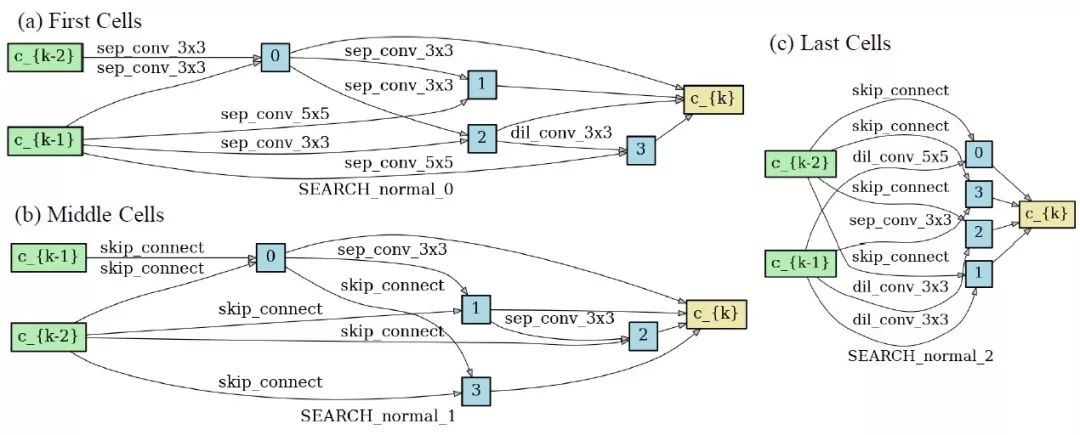
DARTS+:DARTS 搜索为何需要早停?// //
打破 cell 共享网络结构的设定下 , 不同位置的 cell 搜出来的网络结构图
回到 DARTS 的设定 , 如果我们强制不同的 cell 共享同一个网络结构 , 那么 skip-connect 就会从后面的 cell 扩散到前面的 cell 。 当 skip-connect 开始显著变多的时候 , 合作的阶段就转向了竞争的阶段:alpha 开始变坏 , DARTS 开始 collapse 。
值得一提的是 , 两层优化中的合作和竞争现象在其他应用中(比如 GAN , meta-learning 等)也有被观察到 。 以 GAN 为例 , 一个学好的 discriminator 对训练一个 generator 是至关重要的 [7] , 这是 generator 和 discriminator 之间的合作;当输入数据(fake 或 real)落在低维流形上同时 discriminator 过参数化的时候 , discriminator 很容易把生成的 fake data 从 real data 中区分开来 , 同时 generator 也会因为发生梯度消失导致无法生成 real data[8] , 这是 generator 和 discriminator 之间的竞争 。
DARTS+:引入早停机制
为了解决 DARTS 会 collapse 的问题 , 防止 skip-connect 产生过多 , 我们提出一种非常简单而且行之有效的早停机制 , 改进后的 DARTS 算法称之为 DARTS+ 算法 。 本文中我们仍然遵循 DARTS 中 cell 共享网络结构的设定 , 将探索如何打破 cell 网络结构共享留为 future work 。
早停准则:当一个 cell 中出现两个及两个以上的 skip-connect 的时候 , 搜索过程停止 。
DARTS+ 最大的优点就是操作起来非常简单 。 相比于其他改进 DARTS 的算法 , DARTS+ 只需要一点点改动就可以显著地提高性能 , 同时还能直接减少搜索时间 。

DARTS+:DARTS 搜索为何需要早停?// //
上图中的红圈代表各个可学习算子(比如卷积)的 alpha 排序不再改变的时间点(具体细节请参看原文) 。
由于 alpha 值最大的可学习算子对应最后的网络会选择的算子 , 当 alpha 排序稳定时 , 这个算子在最后选择的网络不会出现变化 , 这说明 DARTS 的搜索过程已经充分 。 从上图中蓝线也能看出 , 当过了红圈之后 , 架构的性能开始出现下降 , 从而出现 collapse 问题 。 因此 , 我们可以选择在可学习算子 alpha 排序不再改变(图中红圈处)的时间点附近早停 。 当早停准则满足时(左图中红色虚线) , 基本处于 DARTS 搜索充分处 , 因此在早停准则处停止搜索能够有效防止 DARTS 发生 collapse 。
通过上面的分析 , 我们可以给出一个稍复杂但更为直接的早停准则:
早停准则*:当各个可学习算子(比如卷积)的 alpha 排序足够稳定(比如 10 个 epoch 保持不变)的时候 , 搜索过程停止 。
我们指出 , 第一个早停准则更便于操作 , 而当需要更精准的停止或者引入其他的搜索空间的时候 , 我们可以用早停准则* 来代替 。 由于早停机制解决了 DARTS 搜索中固有存在的问题 , 因此 , 它也可以被用在其它基于 DARTS 的算法中来帮助提高进一步性能 。
值得一提的是 , 近来的一些基于 DARTS 改进的算法其实也隐式地使用了早停的想法 。
P-DARTS[3] 使用了:1)搜 25 个 epoch 来代替原来的 50 个 epoch , 2)在 skip-connects 之后加 dropout , 3)手动把 skip-connects 的数目减到 2 。
Auto-DeepLab[9] 使用了 20 个 epoch 来训架构参数 alpha , 同时发现更多的 epoch(60 , 80 , 100)对性能没有好处 。
PC-DARTS[5] 使用部分通道连接来降低搜索时间 , 因此搜索收敛需要引入更多的 epoch , 从而仍然搜索 50 个 epoch 就是一个隐式的早停机制 。
实验验证
我们在 CIFAR10[10]、CIFAR100[10]、Tiny-ImageNet-200[11] 和 ImageNet[12] 上分类问题进行验证 。 在实验中 , 我们默认使用第一个早停准则 。 具体的实现细节 , 请参看原文 。
实验结果如下:
DARTS+ 在 CIFAR10、CIFAR100 和 ImageNet 上取得 2.32%、14.87% 和 23.7% 的错误率 , 超越一系列现有的 DARTS 改进算法 , 包括 SNAS[2]、P-DARTS[3]、XNAS[4]、PC-DARTS[5] 等 。 在模型大小相当的情况下 , DARTS+ 可以达到与谷歌提出的 EfficientNet-B0[6] 相同的性能 , 但是搜索时间却远远小于 EfficientNet 。 如果再叠加 SE 模块 , mixup 等 , 在 ImageNet 上可以达到 22.5% 的错误率 。
具体的性能指标如下所示:
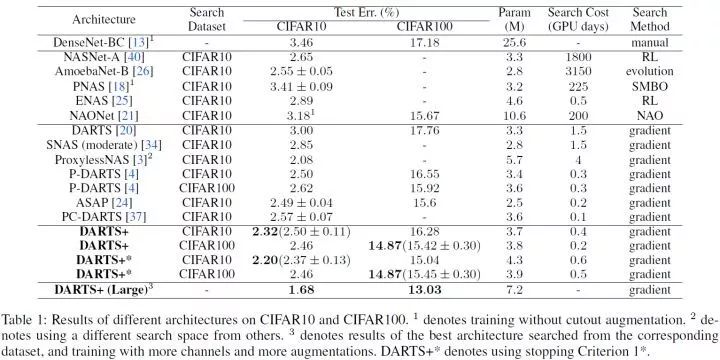
DARTS+:DARTS 搜索为何需要早停?// //
CIFAR10 和 CIFAR100 上的实验结果
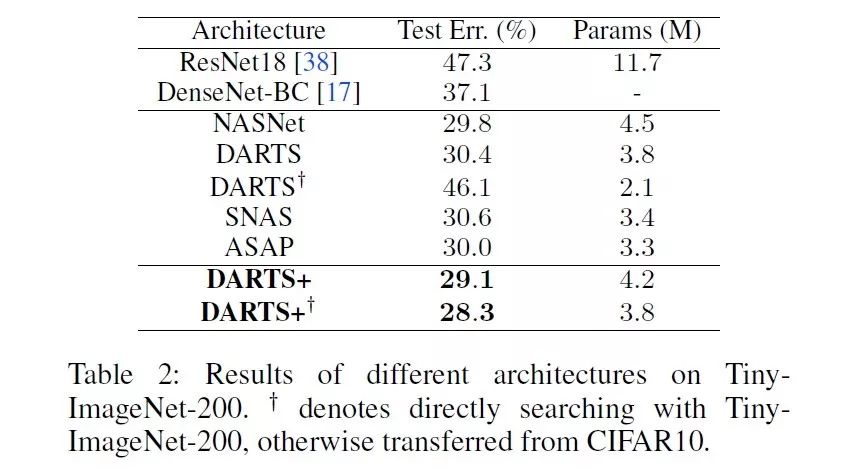
DARTS+:DARTS 搜索为何需要早停?// //
Tiny-ImageNet-200 上的实验结果
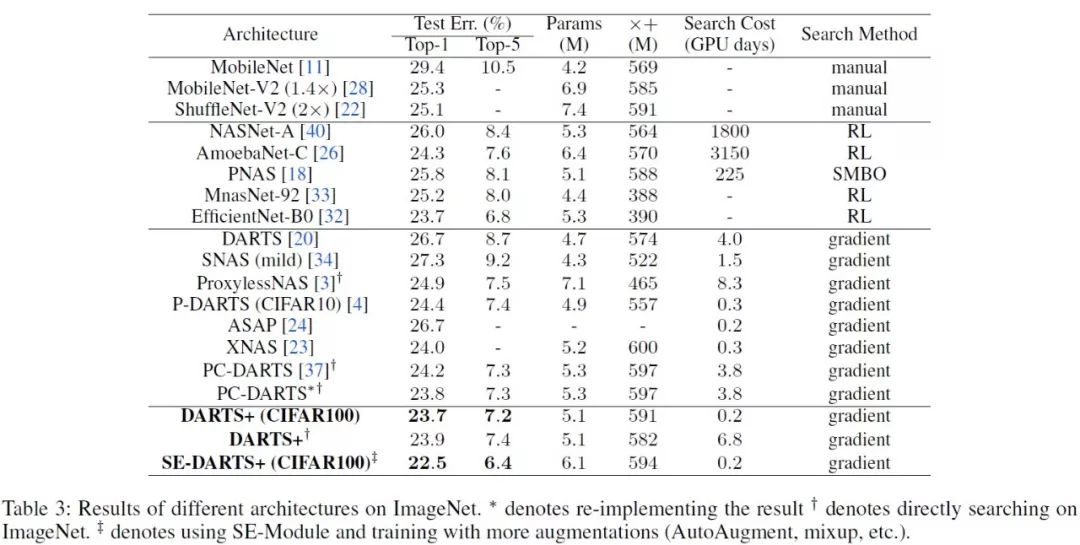
DARTS+:DARTS 搜索为何需要早停?// //
ImageNet 上的实验结果
结语
综上所述 , DARTS+ 简单优雅地解决了 DARTS 算法中固有的 collapse 问题 , 通过引入操作起来十分简单的早停机制 , 既缩短了搜索时间 , 又极大地提高了性能 。 想要进一步提升 DARTS 的性能 , 一个可行的方向是考虑打破 DARTS 中「不同 cell 共享网络架构」的设置 。
本文为机器之心专栏 , 转载请联系本公众号获得授权 。